SD-Zero
- 唠嗑:和导聊的时候发的一篇文,OI 女队陈丹琦的一作,来观摩一下。
正好觉得可以和这一篇 Why Does Self-Distillation (Sometimes)Degrade the Reasoning Capability of LLMs? 一起说。
OPSD/SDPO 的缺陷
两篇文章 SDPO,OPSD在线自蒸馏 同样是在线自蒸馏算法,但前者依赖于强环境反馈,后者依赖于一个很好的金标数据,这就对环境或者数据集有比较严格的限制。
同时,直接依赖于答案的蒸馏算法有 “抄作业” 的嫌疑,这在微软的 这篇(上文链接) 有提及。这篇文章的主要观点是 数学推理 中的一些风格试错词汇(例如 等等 哦对 不太对)实际上对数学推理有比较强的指导作用,同时也维持着模型的泛化能力。
OPSD 中也提到了在做自蒸馏过程中,这一类风格词汇被教师模型淡化了,也就是说:教师模型一眼看到了最终答案和一个大致正确的推理路径,便直接引导模型走这一条推理路径,这减弱了模型的 试错/探索 能力(这告诉我们抄作业是不对的×)。
往夸张的说,这种直接观察答案生成响应的做法类似于在做一个过拟合,两个极端下,强化学习因为除了答案验证什么也不提供,迫使模型自己探索路径,换到这有个教师模型直接告诉你怎么做了,那我还探索个什么,直接抄作业就对了。于是这种训练方法也同时降低了泛化能力,其划定了一个比较清晰的问题规模边界(相当于进舒适区了)。
SD-Zero 概述
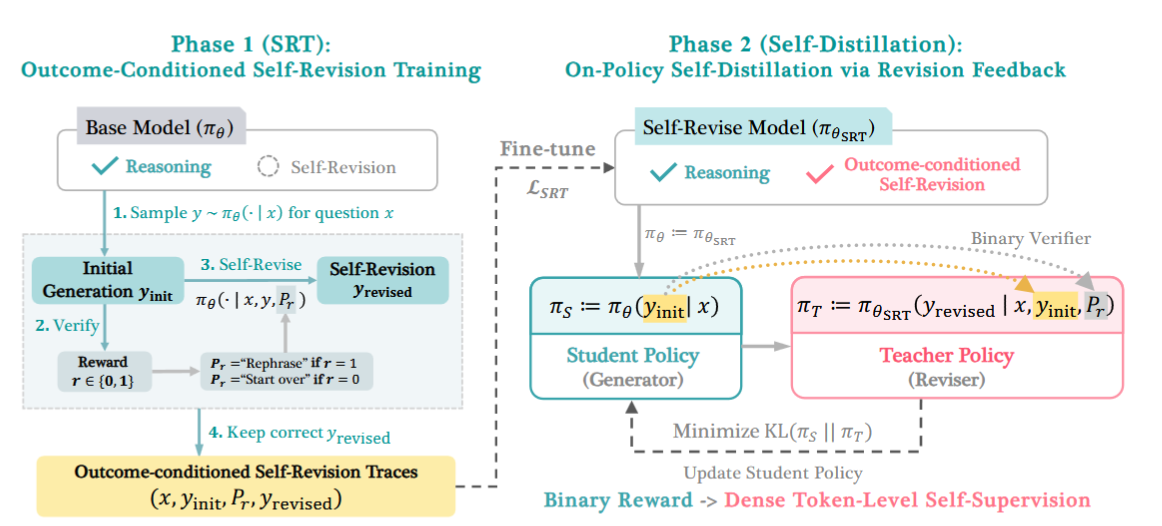
作者认为模型是有能力做自我修正,而不是根据一个金标数据做模仿修正。
SD-Zero 分为两个阶段,SRT 和 SD,模型同时当作生成模型和反思模型。
SRT
对于数据
接着根据该分数走两条路径:
- 若响应正确,设
为一个精简类提示词,引导模型对原回答做精简修正。 - 若响应错误,
为修正类提示词,引导模型重新生成响应修复。
在加入该 prompt 下,同一个模型再生成
接下来做两个损失关注不同能力:
显然前者关注修正能力,后者关注完整输出能力,总损失为:
SRT 类似于做一个 SFT,但又不完全是:数据集是自己生成的,自产自销,更像是一个置信度损失,这时没有所谓的金标测试,完全看模型自己的纠错能力。
于是,就需要引入一些人工的干预,具体而言,对于错误生成的纠错生成,若最终答案还是不对,这条轨迹应该被抛弃,在后续的消融实验中也说明了这一点,对数据集做筛选是重要的。
于是此时,模型同时具有生成和纠错的两个身份。
这也变相引导模型去纠错,改进自己的原始输出。
Self-Distillation
为什么要再做自蒸馏:
- 一方面 SRT 阶段和 RLVR 很相近,都鼓励模型自己探索,这导致输出 token 量会很大,SD 起到一个精简输出的作用。
- 另一方面 SD 可以持续进行,继续做优化(虽然我感觉这一块和前一步的功能相近)。
SD 采用一个新的数据集,上一轮 SRT 的数据集就不用了(因为要 on-policy 嘛)。此时直接训练模型一步输出答案的能力,为了不干扰 rev 反思,将反思模型的参数冻结,只更新学生模型参数(即初始参数一致,但只有学生模型在更新),损失为:
这里有一点不太理解,SRT 的 logits 下前后使用的为同一个学生 sampling,我目前的理解为:如果一个 sampling 是错误的,或需要修正的,在一个前缀下,SRT 会提出另外一个方向的修正引导学生修正,但总归来说整个 sampling 是有多处错误的,只能在多次更新中逐步完成修改(这么想也合理)。
再学习
SD 阶段可以持续学习,定时将
总结和开放方向
算是将 SD 和 RLVR 做了一个结合,其最主要的贡献是抛弃了金标数据,只需要一个验证机制就能自己创造数据自己训练。
同时算法在一定程度上保留了一些风格提示词(虽然是人为加入的),个人认为可以一定程度缓解上文说的 “作弊” 现象,毕竟总体上轨迹都是模型自己探索出来的。
- 作者留下的方向为 thinking 模型,通常 CoT 天然携带错误推理,这是帮助模型做修正的。现在的 SD-Zero 没法很好的区分哪些是对的哪些是错的,强行对 CoT 做蒸馏会降低推理性能。